一、为什么要使用Scrapy框架?
1. Scrapy更强大、高效
2. 采取可读性更强的xpath代替正则
3. 强大的统计和log系统
4. 同时在不同的url上爬取
5. 支持shell方式
二、 安装Scrapy
cmd使用以下命令安装或直接pycharm进行安装
pip install scrapy三、使用Scrapy
1. 项目生成
在你需要生成项目的路径下cmd输入以下命令生成项目
scrapy startproject 项目名称2. 目录文件详解
接着就能在当前目录下看到生成了一个项目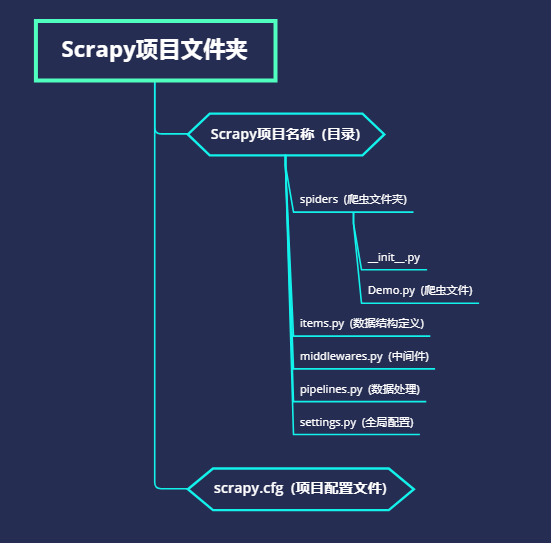
3. 创建爬虫
在爬虫根目录下运行一下命令来创建爬虫
scrapy genspider 爬虫名称 爬虫起始域名运行完以上命令后,可以看到在 spiders 目录下生成了一个py文件,在文件中可以去编写相关逻辑
4. 启动爬虫
4.1 带日志运行
在根目录下运行以下命令即可开始运行爬虫
scrapy crawl 爬虫名称4.2 不带日志运行
在根目录下运行以下命令即可开始运行爬虫
scrapy crawl 爬虫名称 --nolog四、常见问题
1. 动态url
爬虫脚本一般不会只爬取一个页面的内容,故url是动态变化的,但很多的url变化是非常小的,例如url中只需要变化一个页数参数即可,那此时就需要动态的修改start_url的参数,动态url需要在爬虫类中重写一个名称为start_requests的方法,例子如下:
def start_requests(self):
phone = [1, 2, 3]
for i in phone:
url = 'http://cx.shouji.360.cn/phonearea.php?number=%s' % i
yield scrapy.Request(url)2. 检查代码是否有错误
在根目录下输入以下命令
scrapy check3. 查看所有爬虫名称
在根目录下运行以下命令即可查看
scrapy list